QA : Compiler Constructor
| Created by | Borhan |
|---|---|
| Last edited time | |
| Tag |
Resources
- Operator Precedence Function : https://www.youtube.com/watch?v=2sIHp7ny47o&ab_channel=WITSolapur-ProfessionalLearningCommunity
Slide 1-7
- Define language processing system? Briefly describe the phase of language processing system.
The program which translate the program written in a programming language by the user into an executable program is known as language processors.
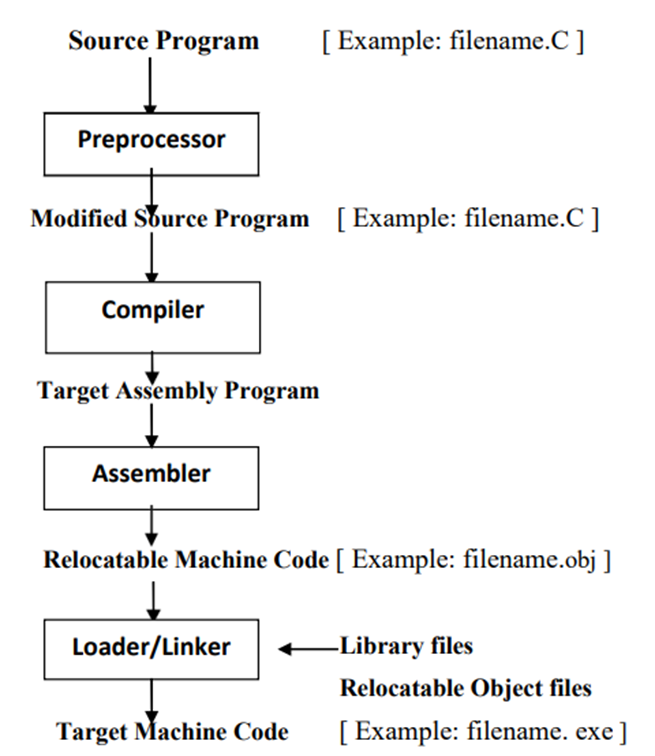
- It includes all header files and also evaluates whether a macro
- The compiler takes the modified code as input and produces the target code as output.
- The assembler takes the target code as input and produces real locatable machine code as output.
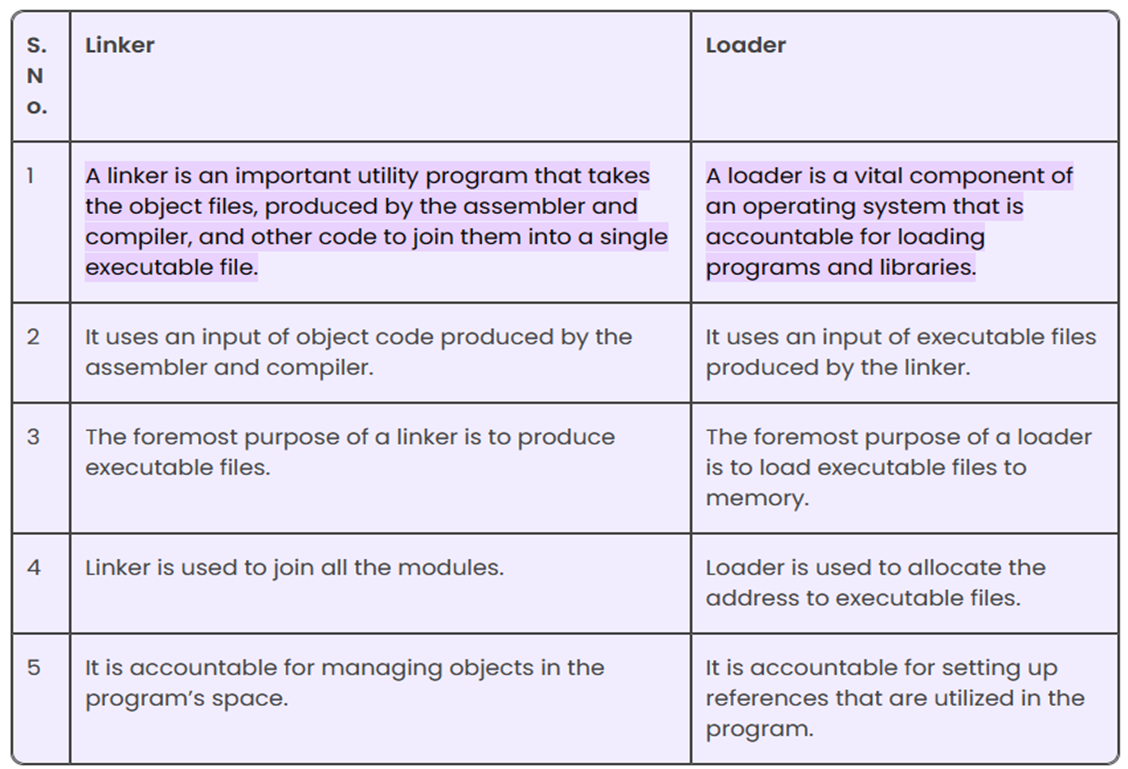
- Linker or link editor is a program that takes a collection of objects (created by assemblers and compilers) and combines them into an executable program.
- The loader keeps the linked program in the main memory.
- Why it is necessary to divide compilation process in to various phases?
| Reason | Explanation |
|---|---|
| Modularity | Each phase handles a specific aspect of compilation, making the process easier to manage and understand. This separation allows for modifications in one phase without affecting others. |
| Error Detection | By breaking down the compilation into phases, errors can be detected and reported at different stages, facilitating easier debugging and correction of code. |
| Optimization | Each phase can apply specific optimizations relevant to that stage, improving overall performance without compromising the functionality of the code. |
| Separation of Concerns | Each phase addresses distinct tasks such as lexical analysis, syntax analysis, semantic analysis, optimization, and code generation, enhancing clarity and focus. |
| Efficiency | Phases can be designed to handle specific tasks in an efficient manner, allowing for parallel processing and better resource utilization. |
| Maintainability | A phased approach allows for easier updates and maintenance, as changes can be localized to specific phases without requiring a complete overhaul of the compiler. |
| Support for Different Languages | Phases can be tailored to support multiple programming languages by adjusting only the relevant parts of the compilation process, making the compiler more versatile. |
- Differentiate between context-free-grammar and regular expression.
| Aspect | Context-Free Grammar (CFG) | Regular Expression (RE) |
|---|---|---|
| Language Class | Context-Free Languages (CFL) | Regular Languages (RL) |
| Expressiveness | More powerful; handles nested structures | Limited; cannot handle nesting |
| Parsing Complexity | Requires complex parsers (e.g., LL, LR) | Parsed with finite automata (simpler) |
| Usage | Syntax of programming languages, nested structures | Pattern matching in text, simple validations |
| Grammar Structure | Defined by production rules in the form of A → α, where A is a non-terminal and α is a sequence of terminals and/or non-terminals. | Defined by a combination of literals, operators (e.g., *, +), and metacharacters. |
Context Free Grammar is formal grammar, the syntax or structure of a formal language can be described using context-free grammar (CFG), a type of formal grammar. The grammar has four tuples: (V,T,P,S).V - It is the collection of variables or non-terminal symbols. | Regular expressions are sequences of characters that define search patterns, primarily used for string matching within texts. |
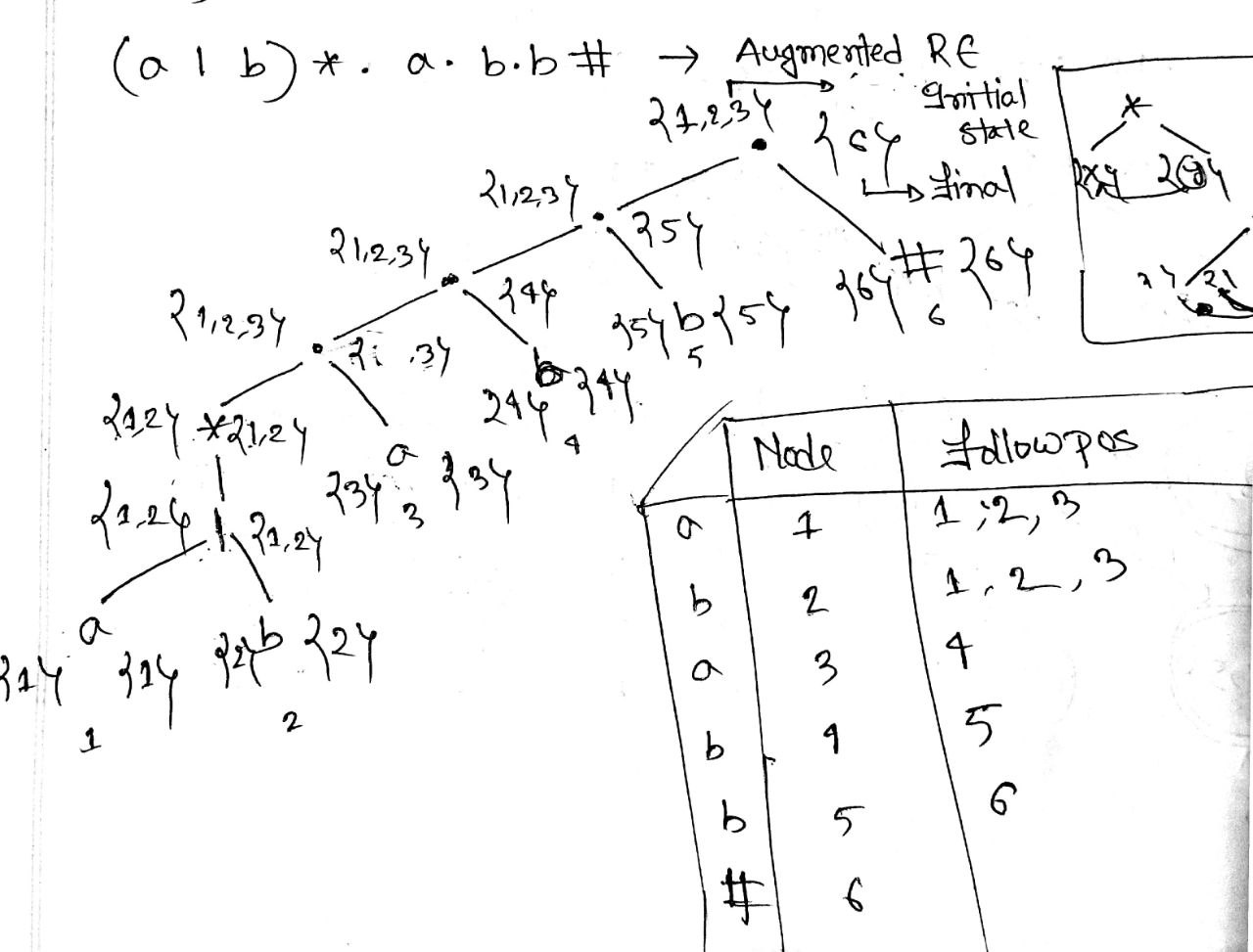
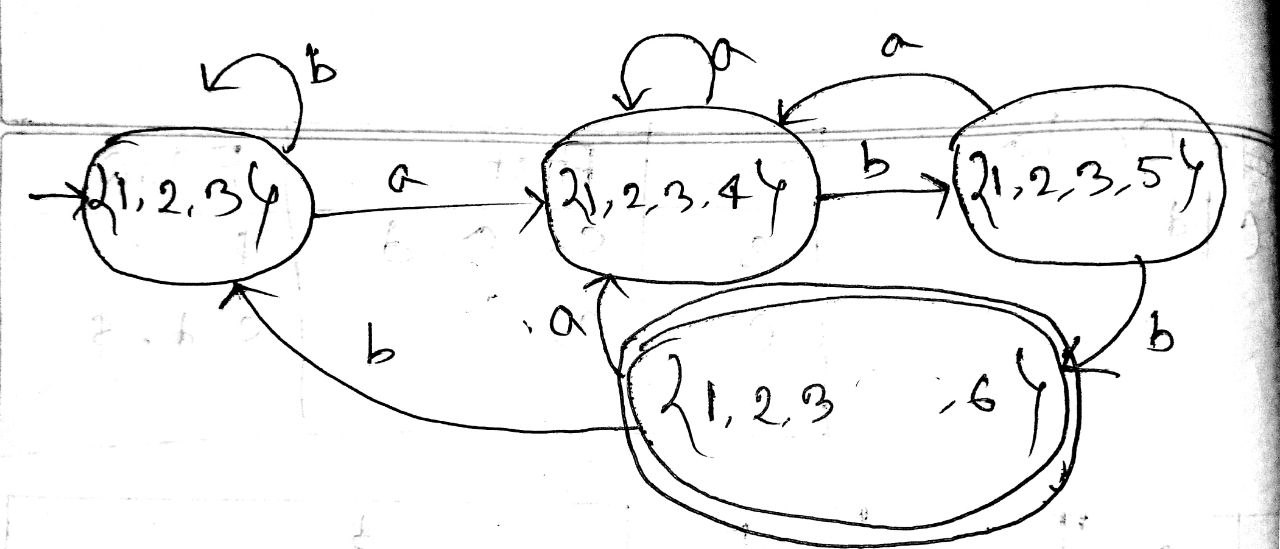
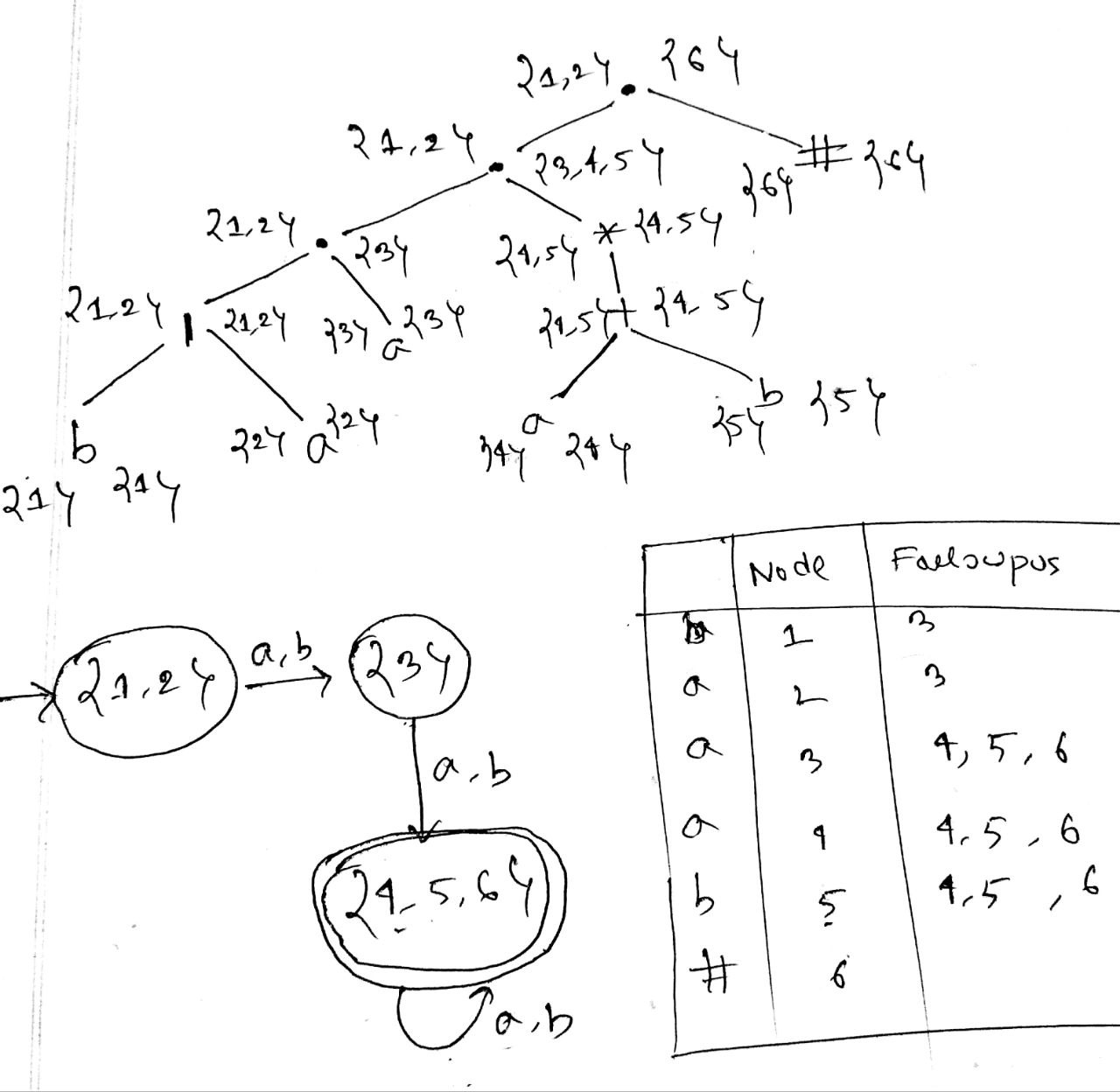
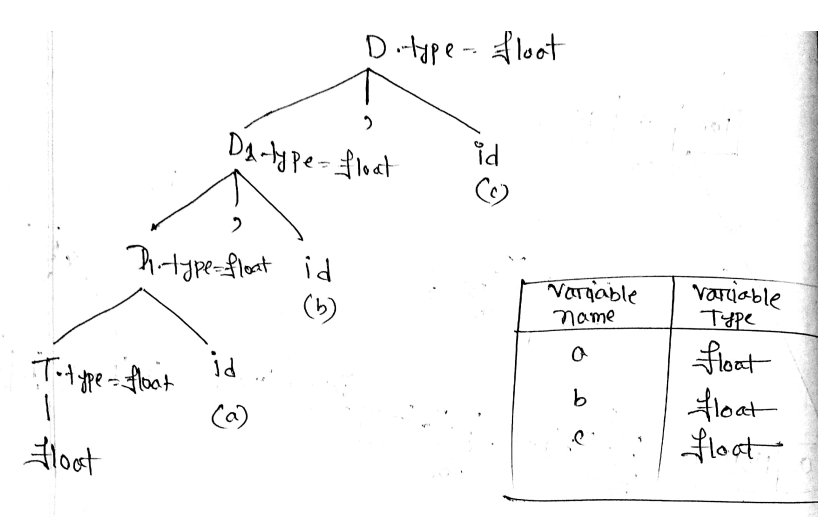
- Write down a regular expression for fractional number and identifier. Draw the -NFA for the regular expression (a|b)*bab.
digits →
letters →
Fractional number →
Identifier →
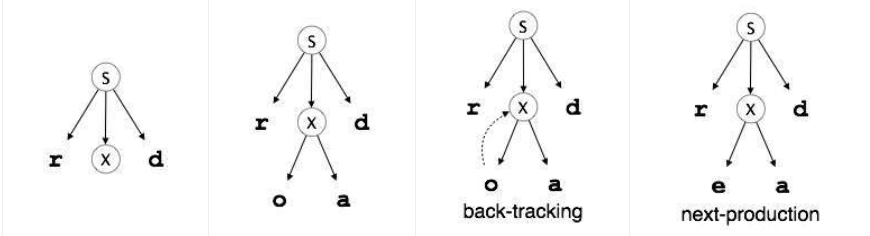
- What is backtracking in top-down parsing?
In Top-Down Parsing with Backtracking, Parser will attempt multiple rules or production to identify the match for input string by backtracking at every step of derivation. So, if the applied production does not give the input string as needed, or it does not match with the needed string, then it can undo that shift.

- Shortly describe scope management of symbol table with proper example
Symbol table is an important data structure created and maintained by compilers in order to store information about the occurrence of various entities such as variable names, function names, objects, classes, interfaces, etc. Symbol table is used by both the analysis and the synthesis parts of a compiler.
A compiler maintains two types of symbol tables: a global symbol table which can be accessed by all the procedures and scope symbol tables that are created for each scope in the program.
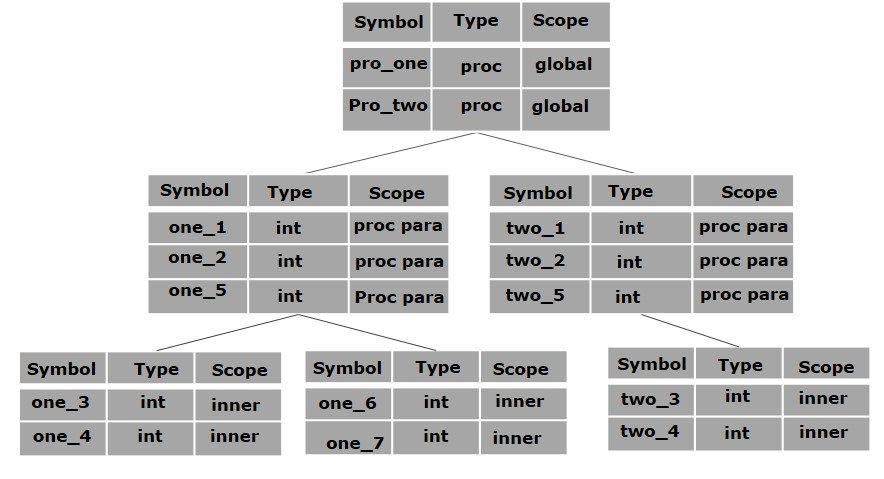
- first a symbol will be searched in the current scope, i.e. current symbol table.
- if a name is found, then search is completed, else it will be searched in the parent symbol table until,
- either the name is found or global symbol table has been searched for the name.
[https://www.tutorialspoint.com/compiler_design/compiler_design_symbol_table.htm]
- Define symbol table. Briefly describe four common error-recovery strategies that can be implemented in the parser to deal with errors in the code
Symbol table is an important data structure created and maintained by compilers in order to store information about the occurrence of various entities such as variable names, function names, objects, classes, interfaces, etc.
- Panic Mode Recovery: The parser skips tokens until it finds a synchronization point, like a semicolon or closing brace. This method prevents further errors by resuming parsing from a safe point, often leading to simpler and faster error recovery.
- In this method, successive characters from the input are removed one at a time until a designated set of synchronizing tokens is found. Synchronizing tokens are deli-meters such as ; or }
- The advantage is that it’s easy to implement and guarantees not to go into an infinite loop
- The disadvantage is that a considerable amount of input is skipped without checking it for additional errors
- Phrase-Level Recovery: The parser makes local corrections, such as inserting, deleting, or replacing tokens to continue parsing. This approach attempts to correct errors by modifying nearby tokens, allowing the parser to proceed with minimal disruption.
- In this method, when a parser encounters an error, it performs the necessary correction on the remaining input so that the rest of the input statement allows the parser to parse ahead.
- The correction can be deletion of extra semicolons, replacing the comma with semicolons, or inserting a missing semicolon.
- While performing correction, utmost care should be taken for not going in an infinite loop.
A disadvantage is that it finds it difficult to handle situations where the actual error occurred before pointing of detection
- Error Productions: The parser includes specific grammar rules (error productions) to handle anticipated errors. When an error production matches an input pattern, the parser can give a more descriptive error message and proceed, aiding in the diagnosis of expected mistakes.

- Global Correction: This approach involves finding the minimal set of changes to the input to make it syntactically correct, often using advanced algorithms. While it provides the best possible correction, it’s computationally expensive and typically not used in real-time compilers
- The parser examines the whole program and tries to find out the closest match for it which is error-free.
- The closest match program has less number of insertions, deletions, and changes of tokens to recover from erroneous input.
- Due to high time and space complexity, this method is not implemented practically
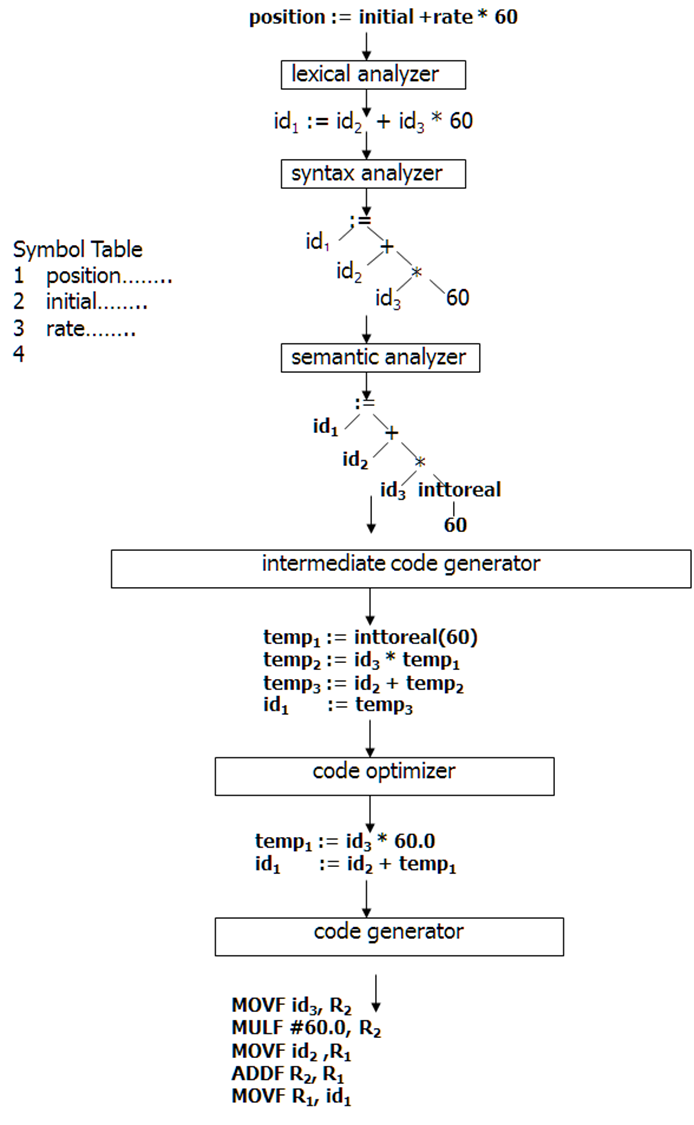
- Show the phases of compiler for the statement position :=initial + rate*60
- What is input buffering? “Buffer pair with sentinels optimizes a code by reducing the number of tests”- do you agree with the statement? Justify your answer accordingly with an example.

- How to recover error using panic mode error recovery in LL(1) parser? Explain.
It is based on the idea of skipping symbols on the input until a token in a selected set of synchronizing tokens appears. The synchronizing set should be chosen so that the parser recovers quickly from error that are likely to occur in practice .

- If the parser looks up the entry M[A, a] and finds that it is blank, then the input symbol a is skipped.
- If the entry is synch, then the nonterminal on the top of the stack is popped in an attempt to resume parsing.
- If a token on the top of the stack does not match the input symbol, then we pop the token from the stack.
- Draw a transition diagram accepting both integer and floating-point numbers with exponentiation.
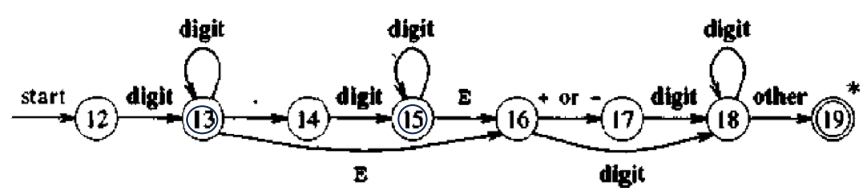

| One Pass Compiler | Two Pass Compiler/Multi pass |
|---|---|
| It performs Translation in one pass | It performs Translation in two pass |
| It scans the entire file only once. | It requires two passes to scan the source file. |
| It doesn’t generate intermediate code | It generates intermediate code |
| Speed fast | Speed slow |
| Time less | Time more |
| Memory more | memory less |
| not portable | portable |


(a) Translator is a program that converts code written in one language into another language. This process is essential in computing because it allows programs written in high-level, human-readable languages to be transformed into low-level machine code, which the computer can execute.
(b)
The lexical analyzer, also known as a scanner or lexer, is the first phase of a compiler. It reads the source code character by character and groups these characters into meaningful sequences called tokens.
The syntax analyzer, also known as the parser, is the second phase of a compiler. It takes the tokens produced by the lexical analyzer and arranges them into a tree-like structure called a parse tree or syntax tree
(c)
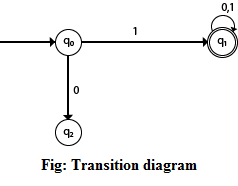
Transition diagram can be interpreted as a flowchart for an algorithm recognizing a language.
Which is constructed by
- There is a node for each state in Q, represented by the circle
- There is a directed edge from a node p to node q labeled if
- Starting state, there is an arrow with no source
- Final states indicating by a double circle

A token is a pair consisting of a token name and an optional attribute value.
A pattern is a description of the form that the lexemes of a token may take [ or match].
A lexeme is a sequence of characters in the source program that matches the pattern for a token and is identified by the lexical analyzer as an instance of that token.


- Error in structure
- Missing operators
- Unbalanced parenthesis
int a = 5 // semicolon is missing
x = (3 + 5; // missing closing parenthesis ')'
y = 3 + * 5; // missing argument between '+' and '*'
(b)What are the points in the parsing process at which an operator-precedence parser can discover syntactic errors?
There are two points in the parsing process at which an operator-precedence parser can discover syntactic error:
- If no precedence relation holds between the terminal on top of the stack and the current input.
- If a handle has been found, but there is no production with this handle as a right side.


- Show the comparisons among error recovery strategies in a lexical analyzer with examples.
Error Recovery Strategy Description Example Pros Cons Panic Mode Skips tokens until it reaches a known, predefined delimiter (e.g., a semicolon ;or end of statement) to resume processing from a safe point.If an error occurs in int x = 10 y;, the analyzer skipsy;and resumes after;.Simple and quick recovery; avoids cascading errors. Loss of tokens; may skip over valid code unintentionally. Error Token Insertion Inserts an artificial token to make the input stream valid and continue processing. In int x = ;, the lexer may insert a placeholder token (e.g.,0) after=to continue.Preserves structure; often used for minor syntax errors. Can lead to inaccuracies by adding tokens that aren't part of the original input. Error Token Deletion Deletes offending tokens to resolve the error and move forward. In int x 10 = 20;, deleting10can allowx = 20;to be parsed correctly.Efficient in certain contexts; reduces clutter by removing extraneous tokens. Risks deleting too many tokens; may alter the intended meaning of the code. Transpose two serial characters Replace a character with another character
- What do you mean by an ambiguous grammar? What are the main reasons of ambiguity and how can ambiguity be eliminated?
Ambiguous grammar is a grammar which produces more than one parse tree for a same string.
The main reasons:
- Precedence
- Associativity
- Dangling else
Remove:
- Rewriting the grammar
- Use ambiguous grammar with additional rules



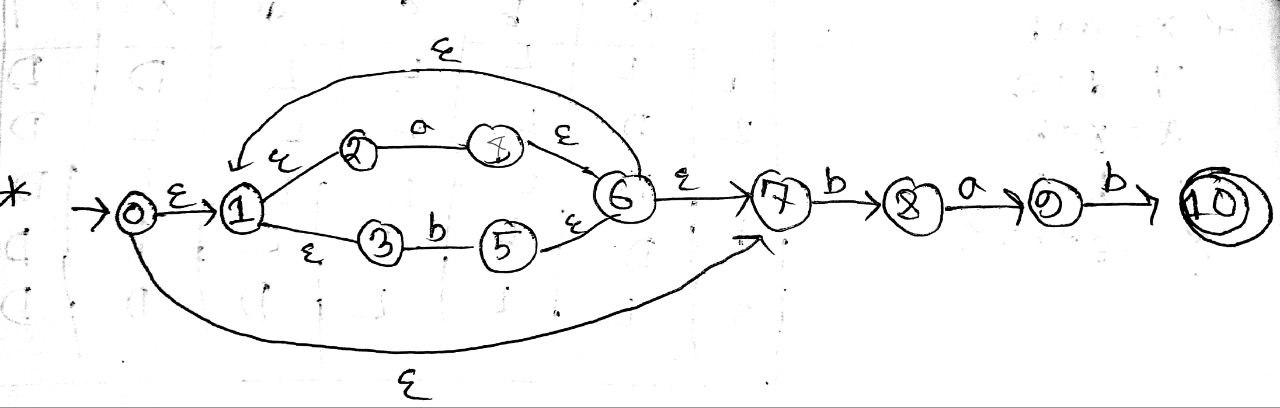
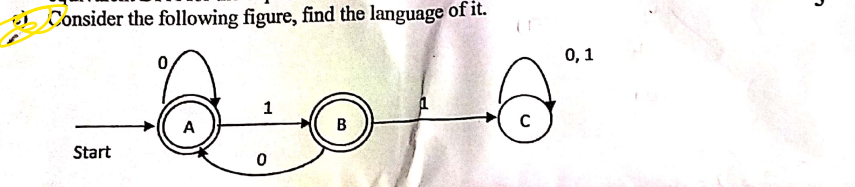

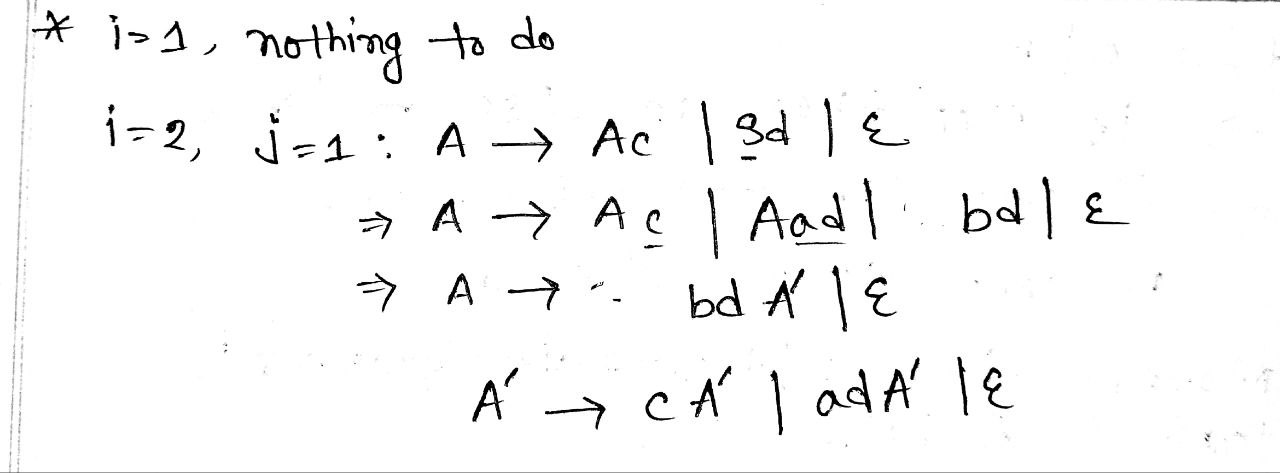
Another one to remove Left recursion
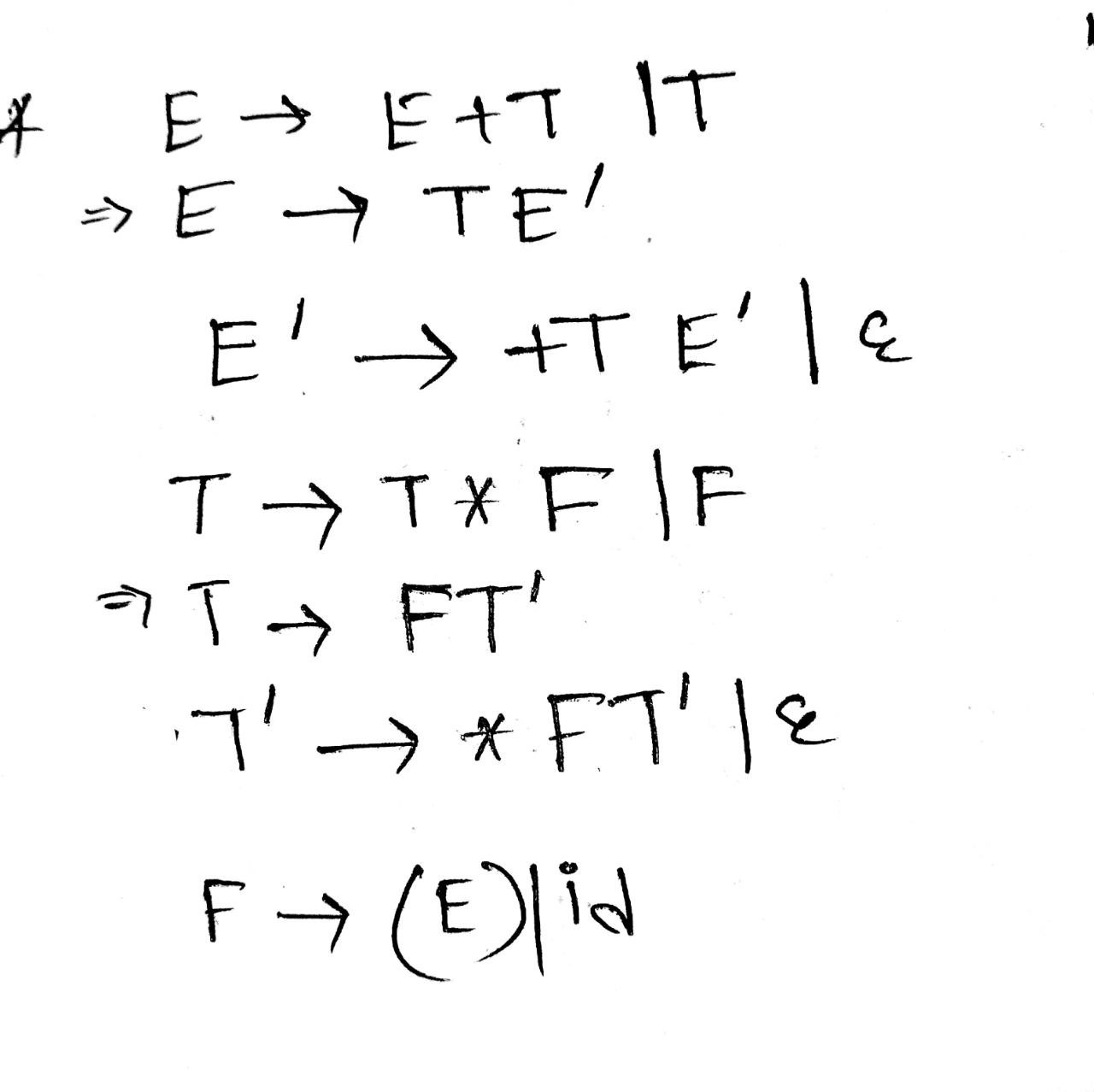



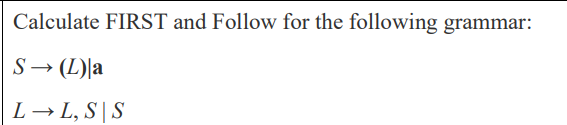
(With check LL(1) or not)
[Used space as separator in FIRST and FOLLOW]
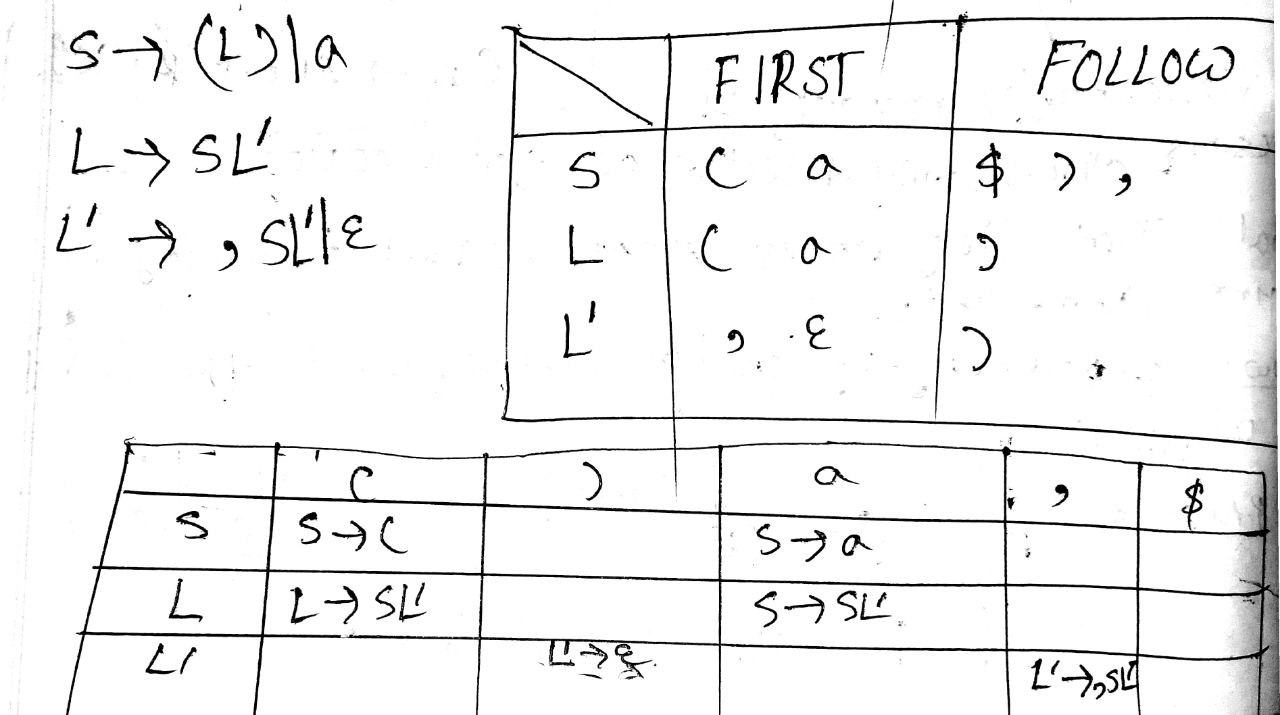

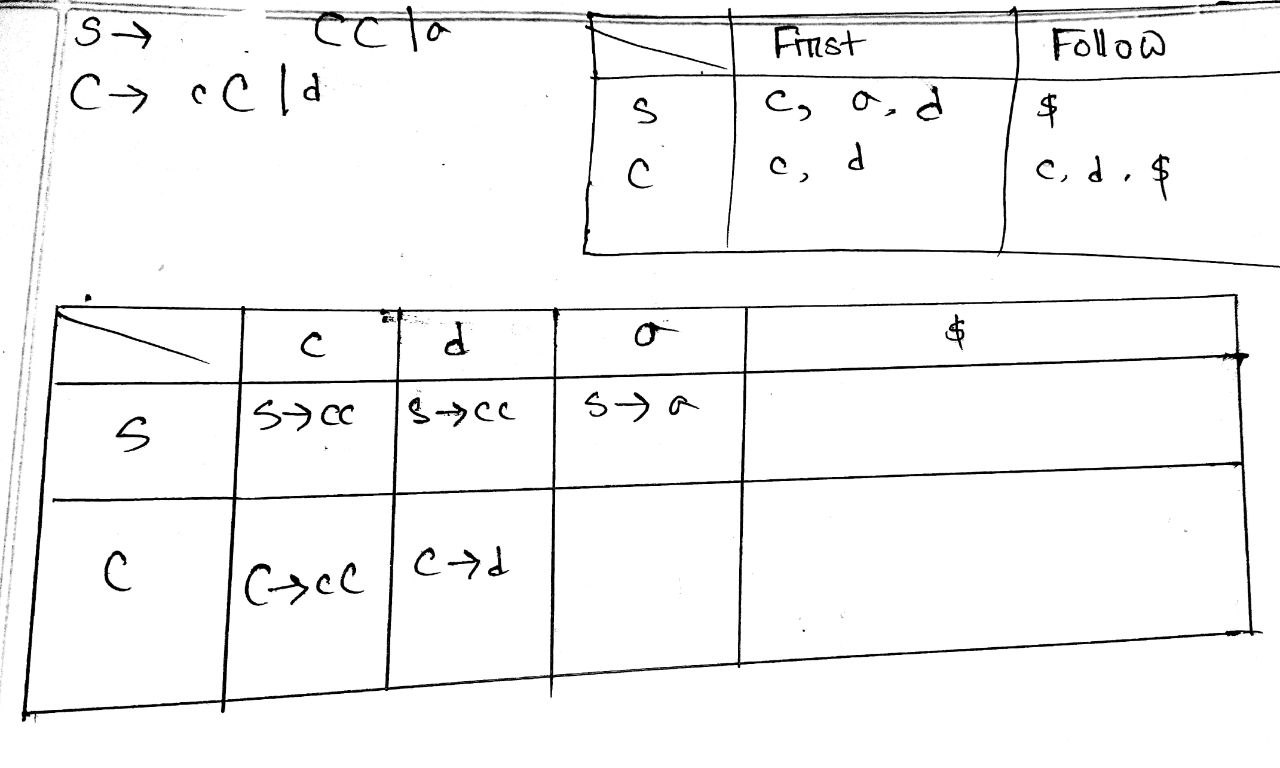



Slide 7-14
Develop an algorithm for constructing an SLR parsing table. Write down the phases of a compiler.
Input : An augmented grammar G’
Output : The SLR parsing table functions action and goto for G’

Phases of a compiler
- Lexical Analysis
- Syntax Analysis
- Semantics Analysis
- Intermediate Code Generation
- Code Optimization
- Target Code Generation
What is precedence function? Show how to construct precedence function with an example.
Precedence functions that map terminal symbols to integers.
Precedence relations between any two operators or symbols in the precedence table can be converted to two precedence functions f & g that map terminals symbols to integers.
- For each terminal a, create this symbol fa and ga
- if a<. b, mark edge from gb to fa
- if a .> b, Mark an edge from fa to gb
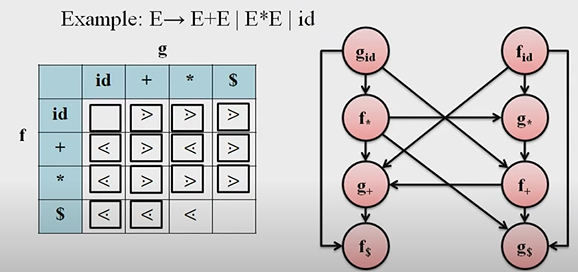
Maximum Length for each Node
| Id | + | * | $ | |
|---|---|---|---|---|
| F | 4 | 2 | 4 | 0 |
| G | 5 | 1 | 3 | 0 |

Solution:
Conditions for a grammar to be an operator grammar :
- No R,H,S of any production has a
- No two non-terminals are adjacent.
We can remove , because it is unreachable.
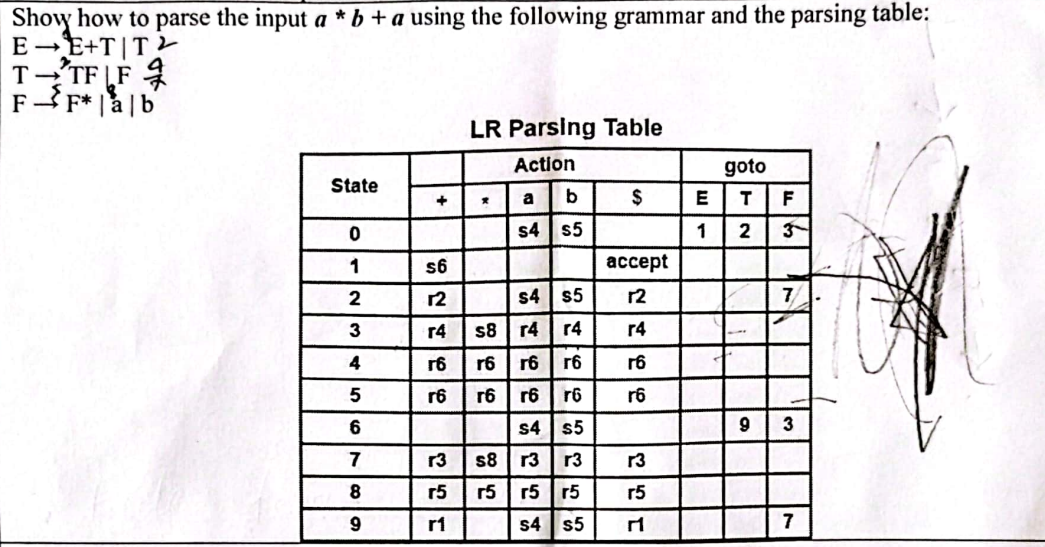
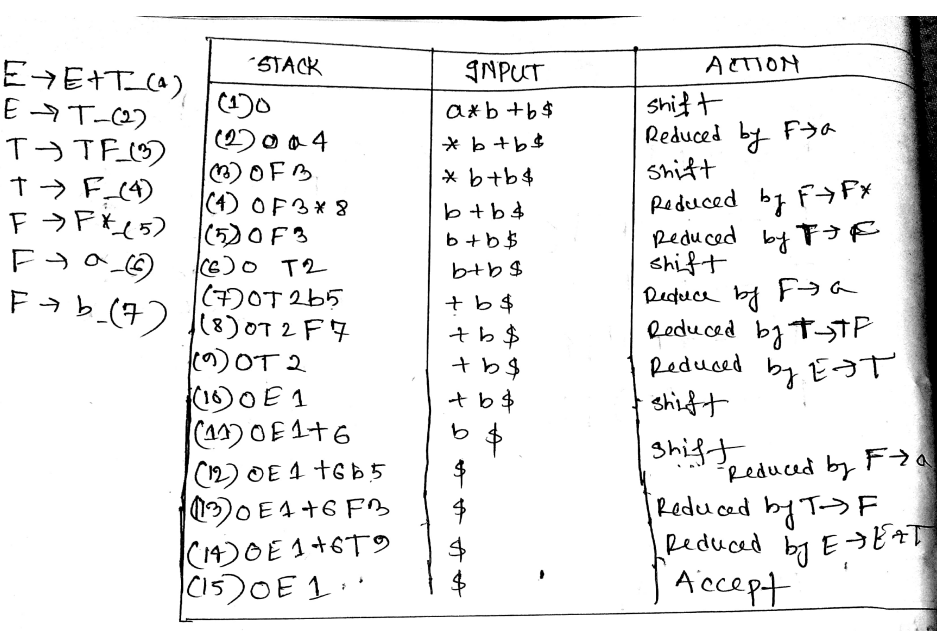
Show the parsing steps for the string id * id+id using operator precedence parsing technique (Note: You must include the precedence table in your answer).
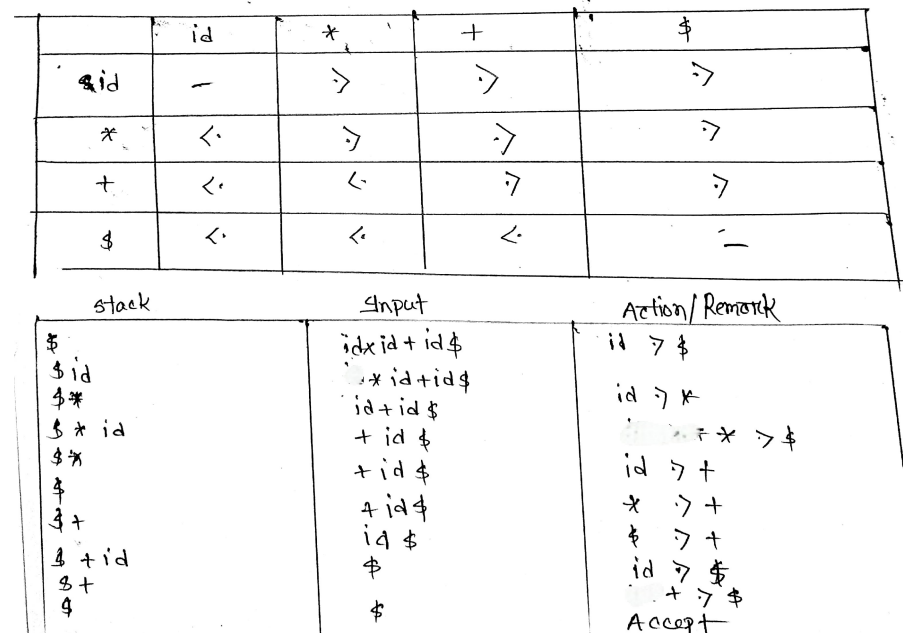
Another Question
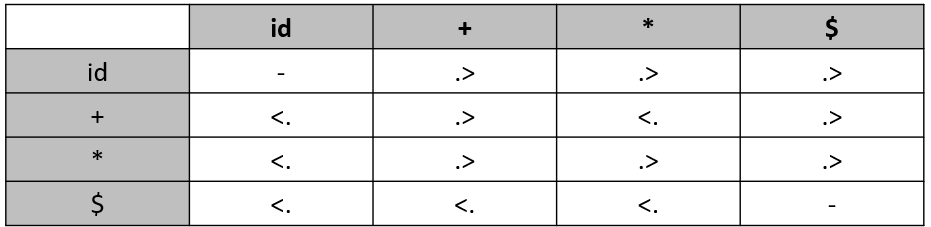
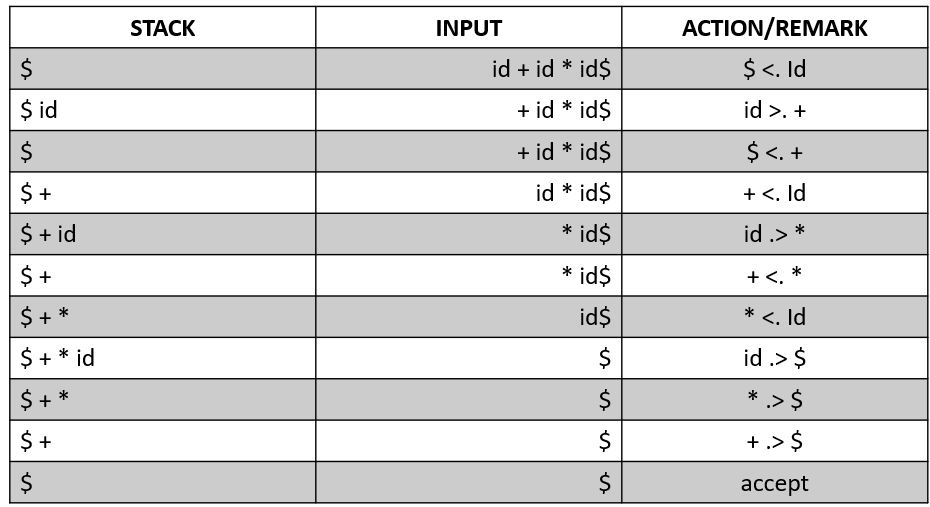

- What do you mean by Shift-Reduce conflict? Explain with an example.
- What do you mean by Reduce-Reduce conflict? Explain with an example.

- Differentiate among LR parsers.
| SLR Parser | LALR Parser | CLR Parser |
|---|---|---|
| Simple LR | Lookahead LR | Canonical LR |
| It is very easy and cheap to implement. | It is also easy and cheap to implement. | It is expensive and difficult to implement. |
| SLR Parser is the smallest in size. | LALR and SLR have the same size. As they have less number of states. | CLR Parser is the largest. As the number of states is very large. |
| Error detection is not immediate in SLR. | Error detection is not immediate in LALR. | Error detection can be done immediately in CLR Parser. |
| SLR fails to produce a parsing table for a certain class of grammars. | It is intermediate in power between SLR and CLR i.e., SLR ≤ LALR ≤ CLR. | It is very powerful and works on a large class of grammar. |
| It requires less time and space complexity. | It requires more time and space complexity. | It also requires more time and space complexity. |
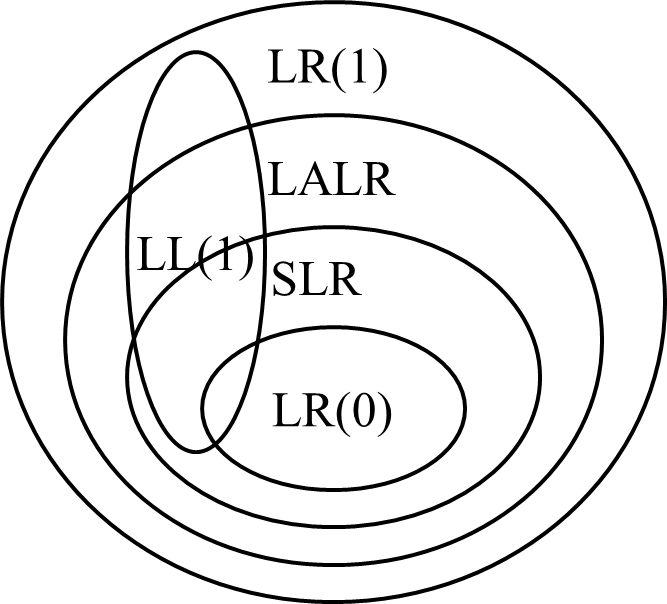
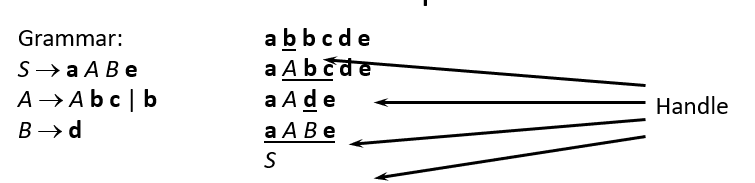
- Define handle with an example. What are the rules for constructing closure of item sets and goto operation?
A handle is a substring of grammar symbol in a right-sentential form that matches a right hand side of a string.
If ‘I’ is a set of items for a grammar G then closure of I is set of items constructed I by two rules:
- Initially, add every item in I to colure (I)
- If is in closure (I) and is a production, then add item to I, if it is not already in existence.
- Apply this rule until no more new items can be added to closure (I)
Goto Operation
- If there is a production then
- Simply shifting of dot (.) one position ahead over the grammar symbol.
- The rule is in I then the same goto function can be written as goto(I, B).
- Goto (I, X), where I is a set of items and X is a grammar symbol, is defined as the closure of the set of all items such that is in I.
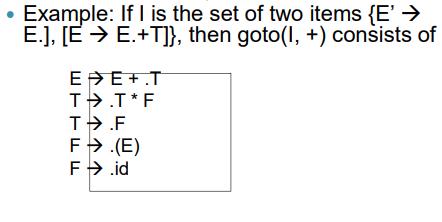

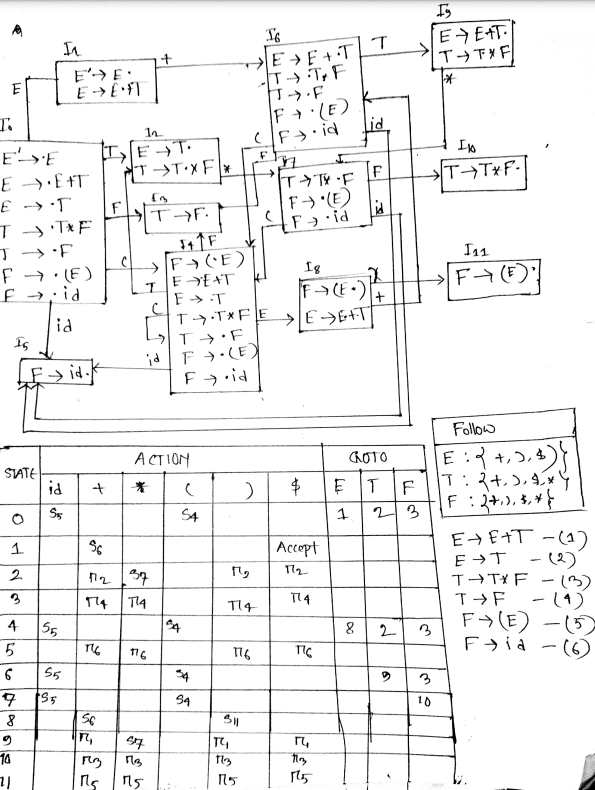

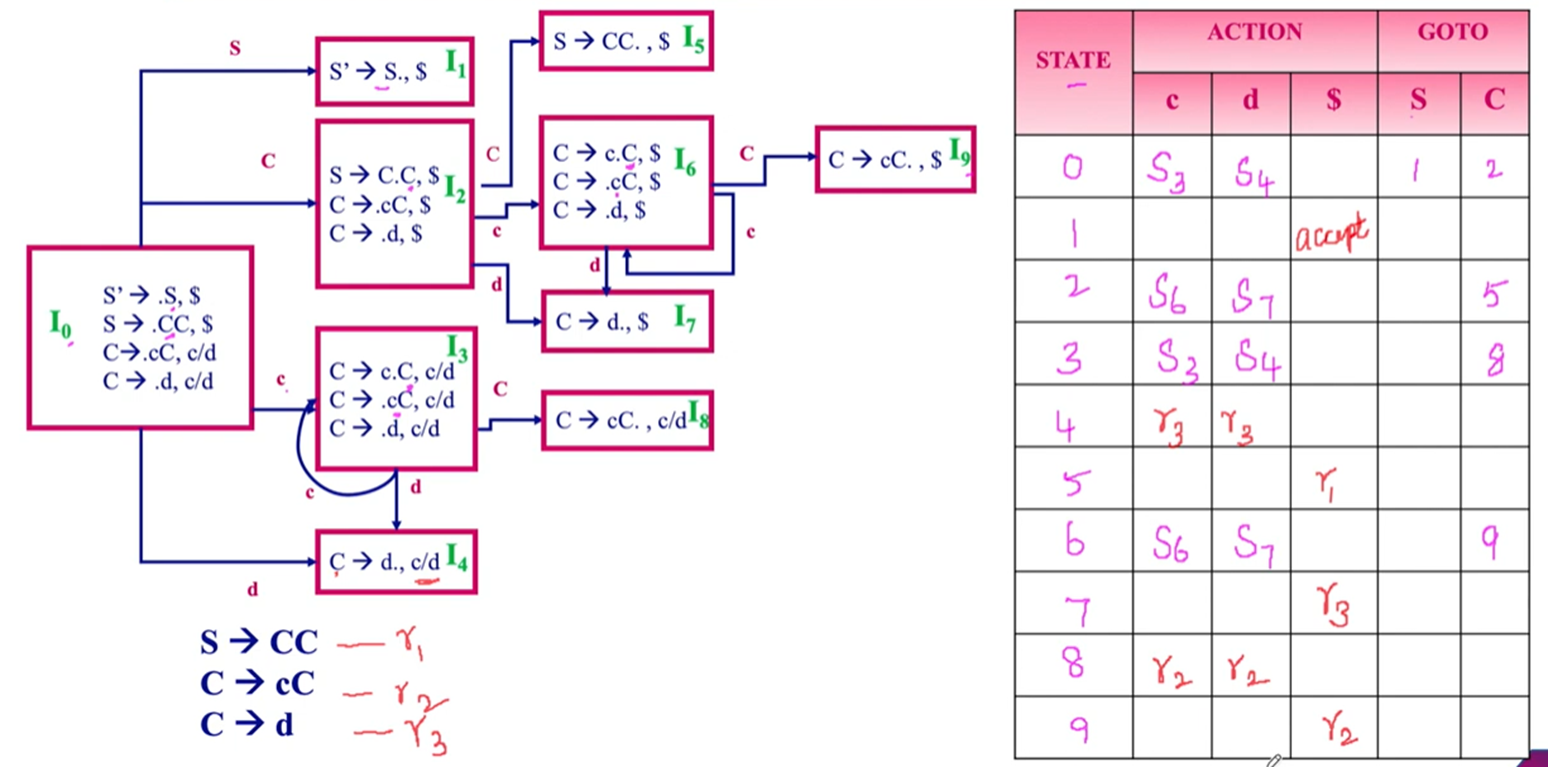

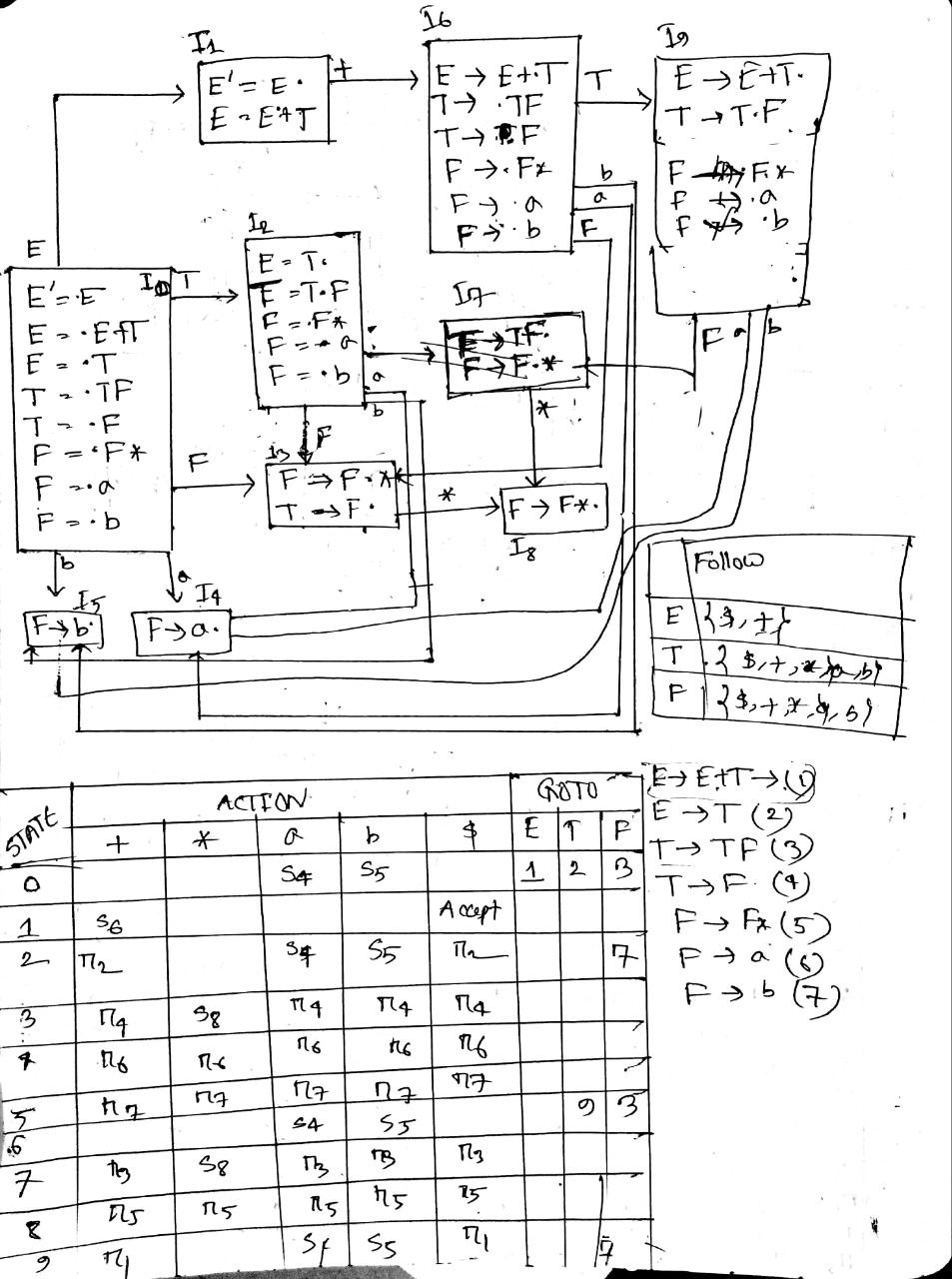

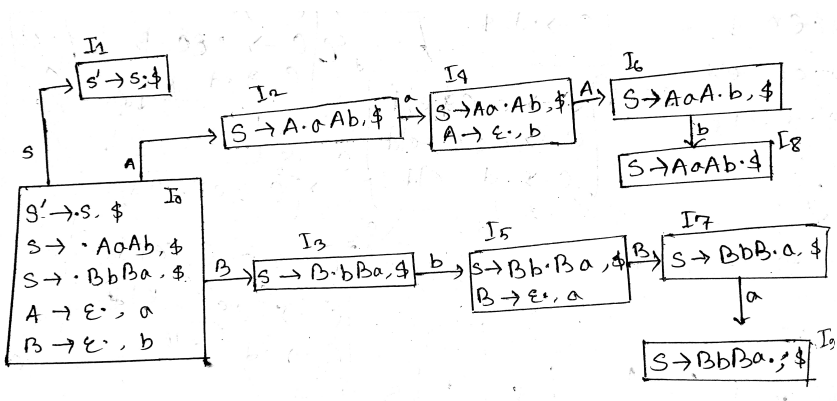


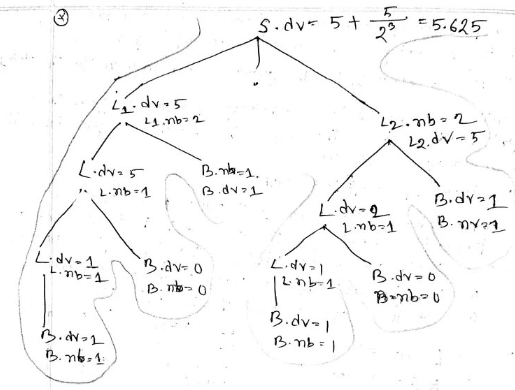
- Contrast quadruples and triples with an example.
- Define indirect triple with an example.
Quadruples
It is a structure which consists of 4 fields namely operator, op1, op2 and result.
op = operand
Pros:
- Statement movement possible
- Quickly access value of temporary variables
Cons:
- Memory inefficient
-(a*b)+(c*d+e)
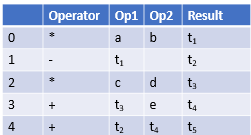
Triples
This representation doesn’t make use of extra temporary variable to represent a single operation.
Pros:
- Memory efficient compared to quadruples
Cons
- Statement movement is not possible
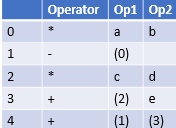
Indirect Triples
This representation makes use of pointer to the listing of all references to computations which is made separately and stored.
Pros
- Statement movement possible
Cons
- Two memory reference is required

A dependency graph is used to represent the flow of information among the attributes in a parse tree.
A dependency graph cannot be cyclic because cycles, or circular dependencies, make it impossible to evaluate the objects in the graph in a valid order.

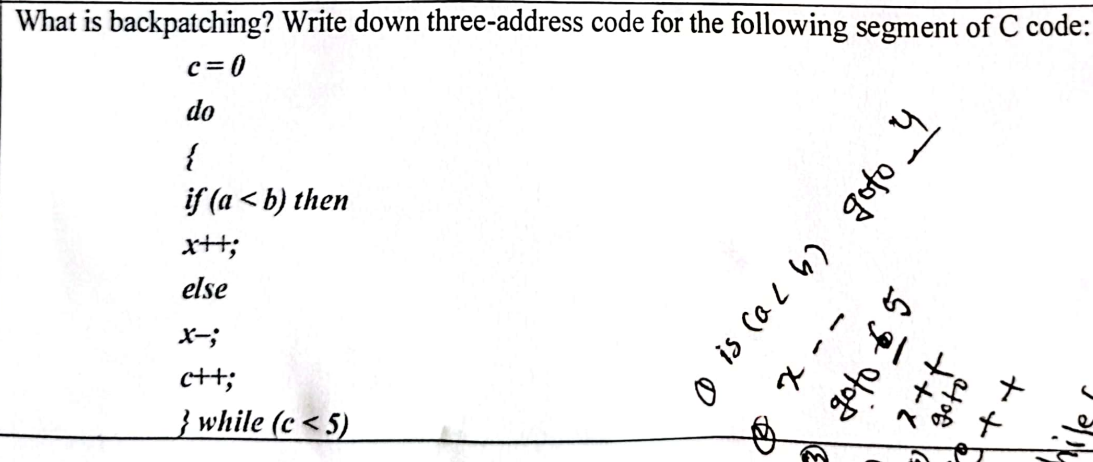
Backpatching is basically a process of fulfilling unspecified information. Backpatching is a method to deal with jumps in the control flow constructs like if statements, loop etc. in the intermediate code generation phase of the compiler.
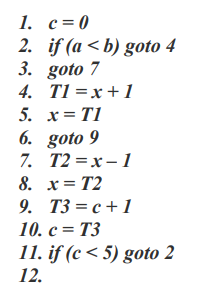

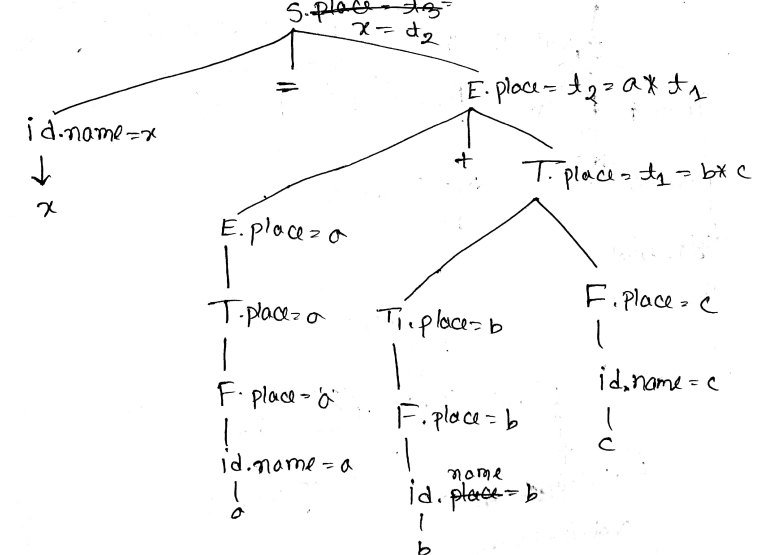
- What do you mean by concrete and abstract syntax tree? Explain with examples.
A parse tree is called a concrete syntax tree. A parse tree pictorially shows how the start symbol of a grammar derives a string in the language.
An abstract syntax tree (AST) is defined by the compiler writer as a more convenient intermediate representation. AST only contains semantics of the code.


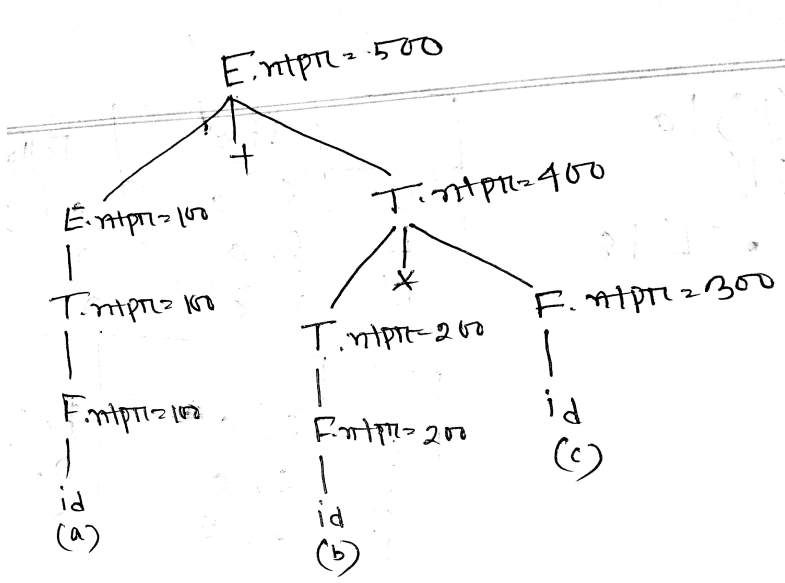

(a)
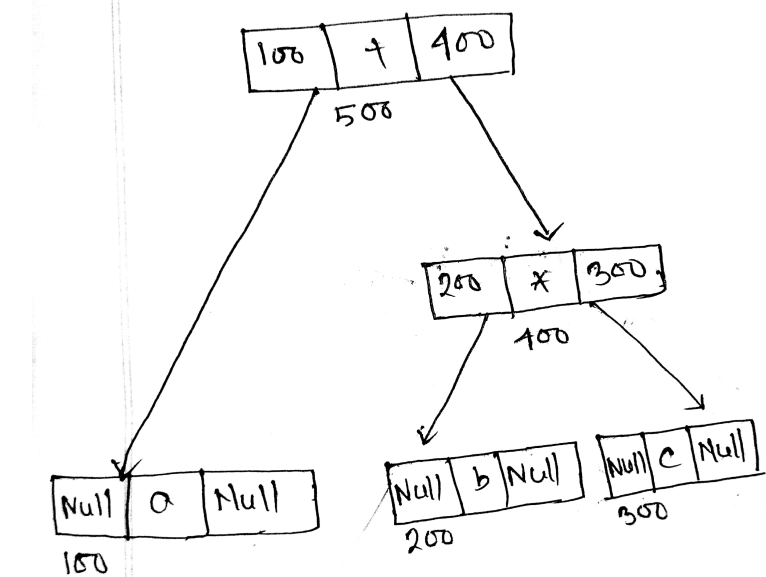
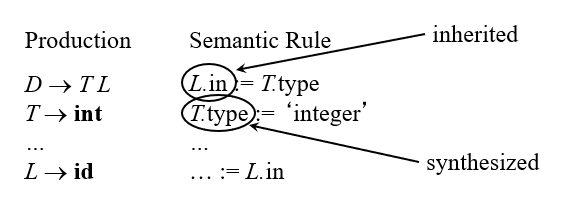
Synthesized: An attribute is said to be synthesized attribute if its parse tree node value is determined by the attribute at child nodes.
Inherited: An attributed is said to be inherited attribute if its parse tree node is determined by the attribute value at parent and/or siblings node.
(b) …
(c) Intermediate Code is a form that serves as a connection between the front end and back end of a compiler, representing the program during various phases Intermediate code can translate the source program into the machine program.
Types of intermediate code:
Linear form
- Postfix notation
- Three address code: A three address statement involves a maximum of three references, consisting of two for operands and one for the result.
Tree
- Syntax tree/Abstract Syntax Tree
- Directed Acyclic Graph


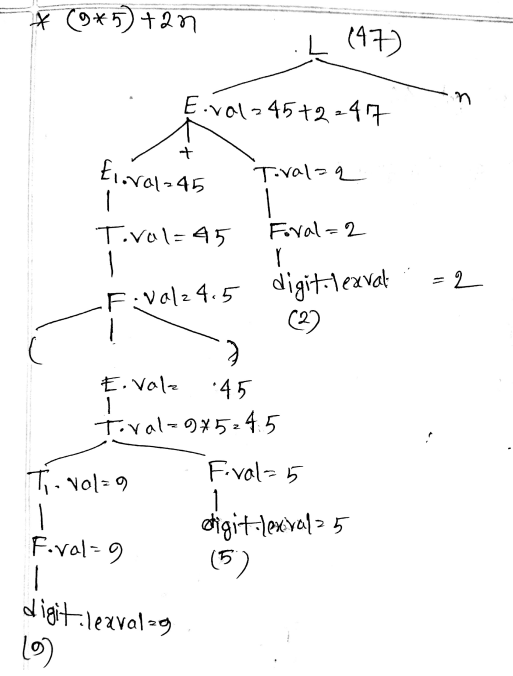

(a)
Quadruples
Pros:
- Statement movement possible
- Quickly access value of temporary variables
Cons:
- Memory inefficient
Triples
Pros:
- Memory efficient compared to quadruples
Cons
- Statement movement is not possible
(b)

(c)

(a)
Types of Code Optimization techniques
- Machine Independent: This code optimization phase attempts to improve the intermediate code to get better target code as the output.
- Loop Optimization
- Constant Folding: Replacing an expression that can be computed at compile time by its value. Example: x=10+5 → x=15
- Redundancy Elimination
- Strength Reduction : Replacing an expensive operator by cheaper one. Example: x/2 → x*0.5, A*2 → A << 1, x^2 → x*x
- Algebraic simplification: Example : x+0=0+x=x, x-0=x
- Machine Dependent: It is done after target code has been generated and when the code is transformed according to the target machine architecture.
- Register Allocation
- Use of addressing modes
- Peephole optimization
Loop Optimization: Loop optimization in code generation involves applying techniques to make loops run more efficiently.
- Frequency Reduction/Code Motion: A statement or expression which can be moved outside the loop body without affecting the semantic of the program.
// Original
for (int i = 0; i < n; i++) {
int temp = a + b;
array[i] = temp * i;
}// Optimized
int temp = a + b; // Moved outside the loop
for (int i = 0; i < n; i++) {
array[i] = temp * i;
}- Loop Unrolling: Reducing the number of times comparison are made in the loop.
for(i=0;i<10;i++){
printf(“Hi”);
}
for(i=0;i<10;i=i+2){
printf(“Hi”);
printf(“Hi”);
}
for(i=0;i<10;i=i+2){
printf(“Hi”);
printf(“Hi”);
}- Loop jamming: Combine or merge the bodies of two loops.
for(i=0;i<5;i++){
a=i+5;
}
for(i=0;i<5;i++){
b=i+10;
}for(i=0;i<5;i++){
a=i+5;
b=i+10;
}(b)
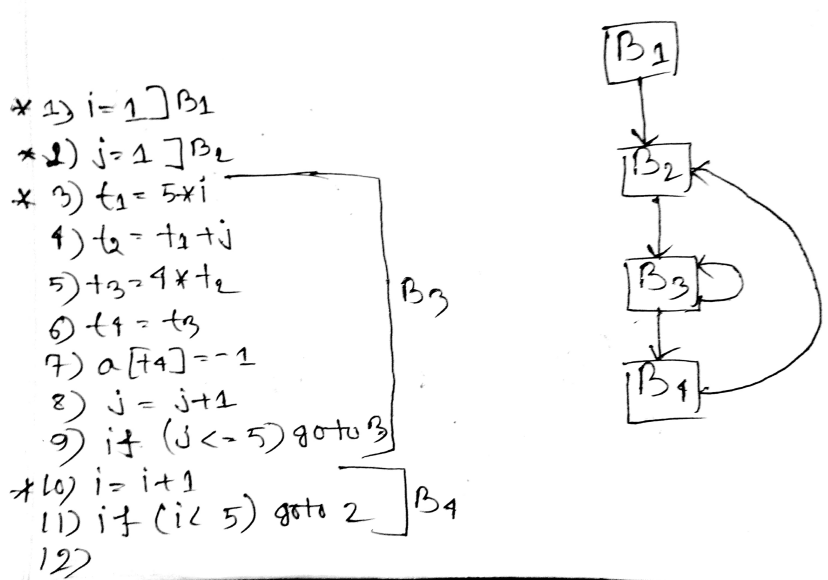
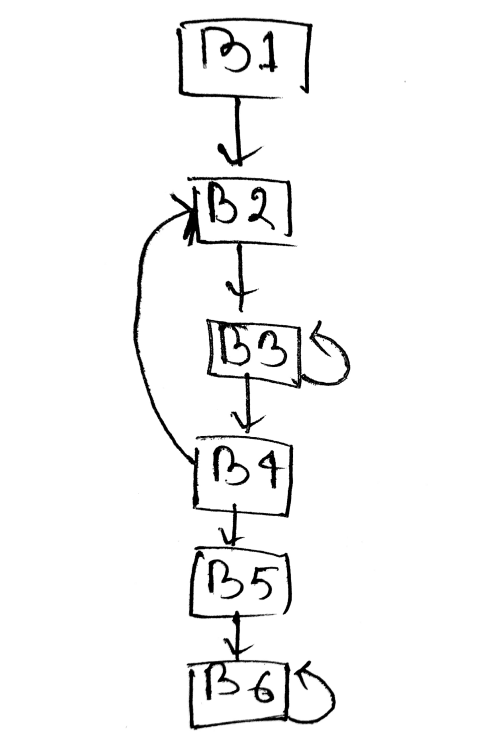
Finding leaders in a basic block
- The first three address instruction in the intermediate code is a leader
- Any instruction that is the target of conditional or unconditional jumps is a leader
- Any instruction that immediately follows a conditional and unconditional jumps is a leader
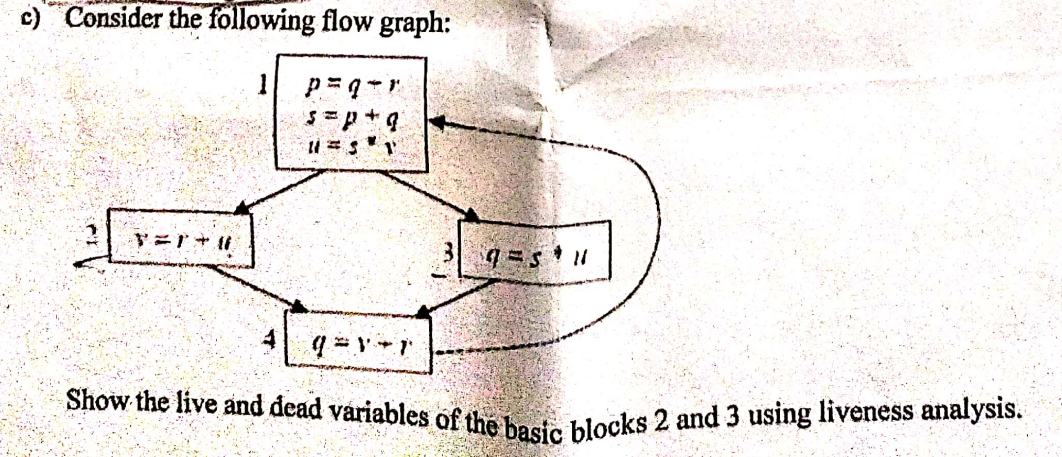
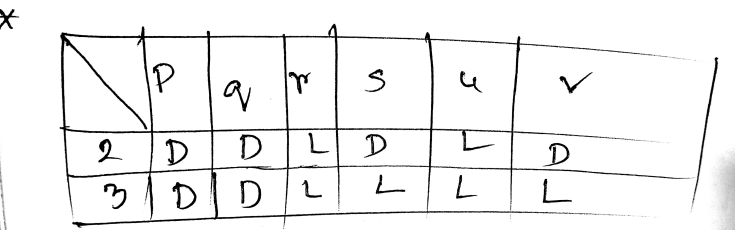
(c)
Liveness analysis or register allocation is a machine dependent optimization technique. The purpose of it is assigning multiple variable to a single register without changing the program behavior.
is a live variable at statement iff
- There is a statement of using
- There is a path from to
- There is no new definition to before

| S-Attributed SDD | L-Attributed SDD |
|---|---|
| A SDD that uses only synthesized attribute is called S-attributed SDD. Ex: A -> BCD {A.i=B.i; A.i=C.i; A.i=D.i} | A SDD that uses both synthesized and inherited attributes is called L-attributed SDD but each inherited attribute is restricted to inherit from parent or left siblings only. Ex: A -> BCD {C.i=A.i; C.i=B.i} Not C.i=D.i |
| Semantic actions are always placed at right end of the production. | Semantic actions are placed anywhere on the R.H.S of the production. |
| Attributes are evaluated with Bottom up parsing. | Attributes are evaluated by traversing parse tree using depth-first, left to right. |


(a)
The run-time environment in a compiler is the setup that created by the compiler to manage program execution. It includes the structures and mechanisms that support that function calls, variable storage, dynamic memory management and overall resource management.
| Allocation Technique | Description | Use Case | Advantages | Limitations |
|---|---|---|---|---|
| Static Allocation | - Fixed memory at compile-time | Global and static variables | No run-time overhead | - No support for dynamic sizes - Doesn’t support dynamic data structure - recursion not supported |
| Stack Allocation | LIFO allocation for function calls | Local variables, function calls | - Efficient for function calls - Recursion supported | - Limited to static sizes - Doesn’t support dynamic data structure |
| Heap Allocation | Dynamic memory at run-time | Dynamic data structures | - Flexible, supports dynamic sizes - Allocation and deallocation will be done at anytime based on user requirement - Recursion supported | Requires careful management |
(b)
An activation tree is a conceptual tool used in compiler design and program analysis to represent the sequence of function or procedure calls in a program, based on its control follow.
Properties
- Each node represents an activation of a procedure
- The root shows the activation of the main function
- The node for procedure x is the parent of node for procedure y if and only if the control flows from x to procedure y.
An activation record is the contiguous block of storage that manages information required by a single execution of a procedure.
Activation Record Units
- Temporaries: The temporary values, such as those arising in the evaluation of expression, are stored in the field for temporaries
- Local data: The field for local data holds data that is local to an execution of a procedure.
- Save Machine States: The field for Saved Machine Status holds information about the state of the machine just before the procedure is called.
- Access Link: It refers to information in other activation records that is not local. The main purpose of this is to access the data which is not present in the local scope of the activation record. (In which outer function the function is defined)
- Control Link: It refers to an activation record of the caller. They are used for links and saved status. (Which function is called in the function)
- Parameter List: The field for parameters list is used by the calling procedure parameters to supply parameters to the called procedure.
- Return value: The field for the return value is used by the called procedure to return value to the calling procedure.
(c)


(a)
Peephole optimization is an optimization technique performed on a small set of compiler-generated instructions, known as a peephole or window.
How the optimization performed
- Identify the Peephole: Compiler finds the small sections of the generated code that needs optimization.
- Apply the Optimization rule: After identification, the compiler applies a predefined set of optimization rules to the instruction in the peephole.
- Evaluate the result: After applying the optimization rule, the compiler evaluates the optimized code to check whether the changes make the code better than the original in terms of speed, size or memory.
- Repeat: The process is repeated by finding new peepholes and applying the optimization rule.
(b)

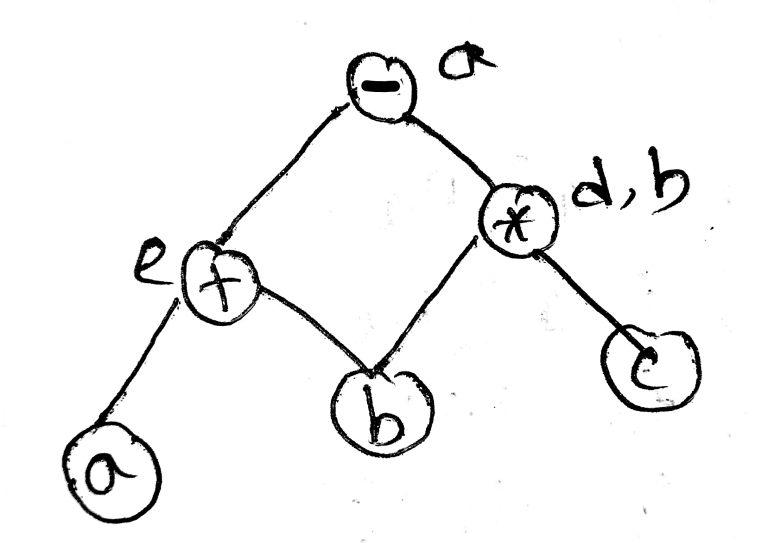
- Show Syntax tree and DAG for the expression a + a * (b – c) + (b – c) * d. Show the benefits of DAG over syntax tree using three address code.
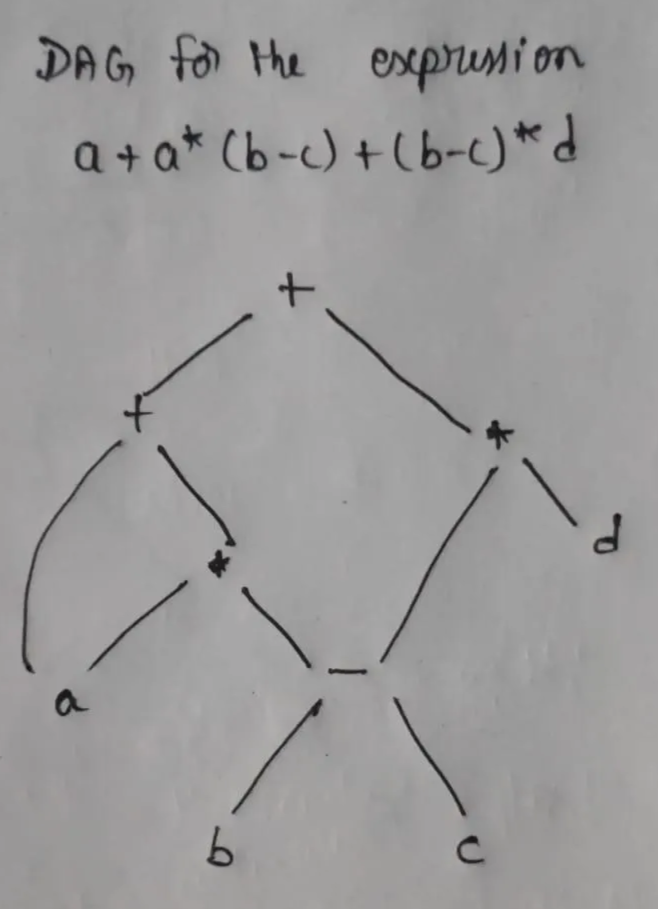
Benefits of using Directed Acyclic Graphs (DAGs) over syntax trees for generating Three Address Code, in point form:
- Redundancy Elimination: DAGs remove duplicate sub-expressions by sharing common nodes, while syntax trees may repeat identical expressions.
- Memory Efficiency: DAGs require less memory as they represent shared sub-expressions with a single node, unlike syntax trees, which store duplicates.
- Simplified Optimization: DAGs make optimizations (like constant folding and common sub-expression elimination) easier, as shared computations are directly represented.
- Reduced Code Size: Code generation from a DAG can produce fewer instructions since it avoids recomputing repeated expressions, whereas syntax trees often generate redundant code.
- Clear Evaluation Order: DAGs clarify dependency relationships, making it easier to determine the correct order for computation, which is less straightforward with syntax trees.
- Improved Intermediate Representation: DAGs focus on computational dependencies rather than structural syntax, streamlining transformations for compiler optimizations.